With the advancements in denoising diffusion probabilistic models (DDPMs), image inpainting has undergone
a significant evolution, transitioning from filling information based on nearby regions to generating
content conditioned on various factors such as text, exemplar images, sketches, etc. However, existing
methods often necessitate fine-tuning of the model or concatenation of latent vectors, leading to
drawbacks such as generation failure due to overfitting and inconsistent foreground generation. In this
paper, we argue that the current large models are powerful enough to generate realistic images without
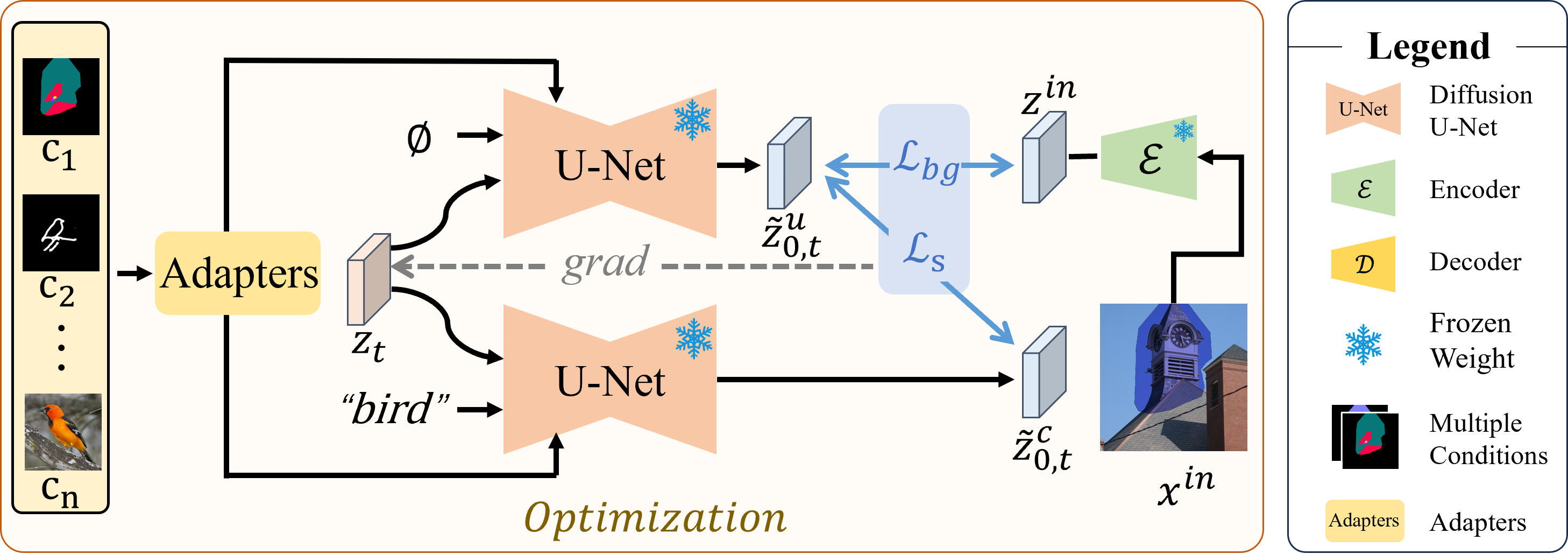
further tuning. Hence, we introduce PILOT (inPainting vIa
Latent OpTimization), an optimization approach grounded
on a novel semantic centralization and background loss to identify latent spaces capable of generating
inpainted regions that exhibit high fidelity to user-provided prompts while maintaining coherence with the
background region. Crucially, our method seamlessly integrates with any pre-trained model, including
ControlNet and DreamBooth, making it suitable for deployment in multi-modal editing tools. Our qualitative
and quantitative evaluations demonstrate that our method outperforms existing approaches by generating
more coherent, diverse, and faithful inpainted regions to the provided prompts.